Text statistics
Hi guys! Here is just a very small blog. Last time we presented some JSON files where we counted the hieroglyphs of texts. These results are now also published in the ORAEC Corpus. Each ORAEC text now has a text statistics subpage. There you can find the numbers mentioned last time: text length, 10 most frequent characters, information about the inequality. Look at oraec17 as an example:
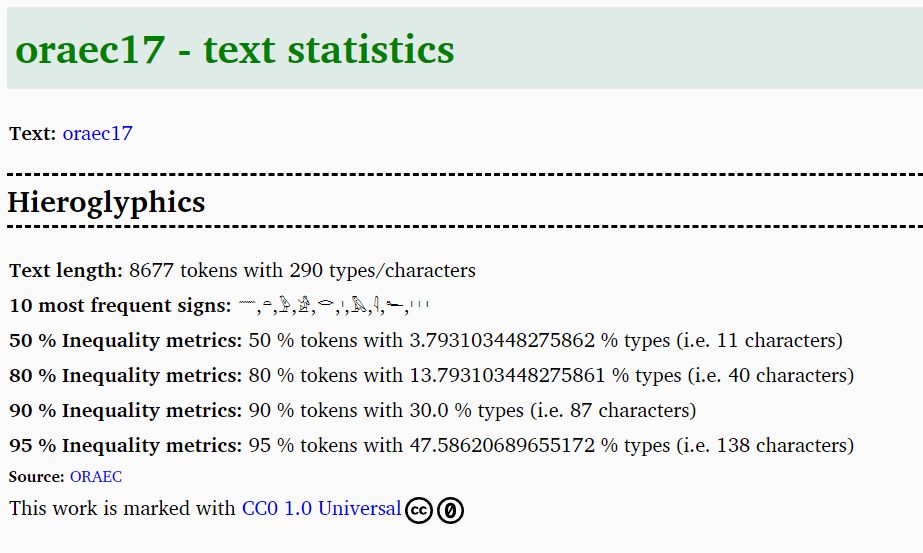
So the text is 8677 signs long and consists of 290 different characters. The most common characters are 𓈖, 𓏏, 𓅱, 𓀀, 𓂋, 𓏤, 𓅓, 𓇋, 𓆑, 𓏥.
You can go directly to the text statistics page by appending _statistics to the ORAEC number. So for oraec17 from our example, the URL is https://oraec.github.io/corpus/oraec17_statistics.html. Or you can simply click on the link on the text page.
We want to extend this page: type token ratio, tf-idf are first extensions we are planning. Do you have special wishes? Certain measures for lexical richness e.g.? Mail us, how we should fill the statistics page.
This work is marked with CC0 1.0 Universal![]()
![]()